Getting Going
When talking about public cloud you will likely know the big players. Between Google (GCP), Amazon (AWS) and Microsoft (Azure) there are a whole host of services on offer. We are primarily interested in the ‘Public Cloud: Trained’ model services, those are the custom models that we train with our customers’ datasets and are proprietary to them. These all use natural language processing (NLP) as the underlying approach and, depending on the use case, we use the following solutions for this:
- Microsoft: Form Recogniser\
- Google: AutoML (Transitioning to VertexML)
- Amazon: Amazon Comprehend
The choice of which to use will often come down to the current technology landscape you have/are adopting. We generally find that all are comparable in terms of accuracy.
For the discussion below, we have chosen Google as we have found this relatively simple to work with and we have been impressed by the results. It’s worth noting you don’t have to stick with 1 provider of course, all of these services are designed to be used as microservices and can be integrated with (almost) any other solution.
The documents we’ve chosen are Quarterly Performance Reports sourced from email attached PDFs.
Training The Models
Our training approach is to be as automated as possible. If you have the historic data, in the correct structure, then building a utility that will create the training set (in this case JSONL file(s)) from that data is of course preferable. The alternative would be to manually label the documents, which depending on the size of the training set and complexity of documents may not be appropriate. Our experience tells us that you will need at least 100 labelled docs for your model.
A word on retraining and Human in the Loop
Retraining/iteratively training models is a key part of improving the algorithm over time. The two approaches here are to manually retrain periodically, vs ongoing human in the loop training.
Periodic, manual training is simply reviewing results and manually labelling up new items to add to the training set on a set schedule, say quarterly.
By human in the loop, I am referring to building continuous training into the business process. Staff are already being paid to correct, validate & input data – why not take ML into this to build a highly accurate model over time, almost for free.
Evaluating & Running the Models
The evaluation of these models is inherently part of the training, along with the validation and creation itself.
We created the model below by providing a training set and an evaluation set (of labels, or docs to use layman’s terms). The evaluation set essentially attempts to find the best possible neural network to apply to the training set. Once trained, a test set is run, and results generated.
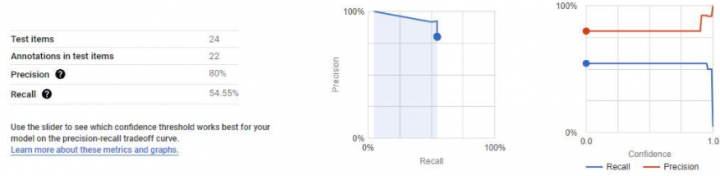
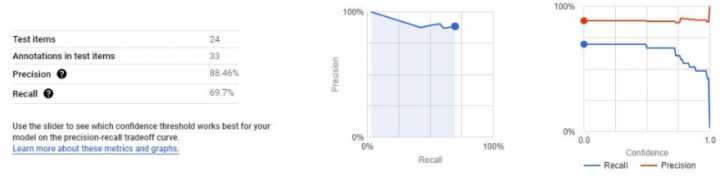
Our New ‘First’ Model
Reading the Results
When analysing models, the two key metrics to consider are precision and recall, so what do they mean?
Precision: This is the comparison of positives within a model. It looks at the percentage of true positives against false positives.
So a model of 80% precision would mean that 80 % of the positive predictions were correct:
100 items were predicted to be positive, however 20 of them should have been negative.
Recall: Recall is the flip to precision, so recall looks at the percentage of false negatives, that is missed correct values if you will.
So a model of 80% recall would mean that 80% of the negative predictions were correct:
100 labels were predicted to be negative, however 20 should have been positive
It’s clear that both the above are important to consider, and whether false positives or false negatives are a preference will depend on the use case in question.